In the 2024 Stack Overflow Developer Survey, 76% of developers reported using AI tools at work, yet only 43% trusted their accuracy. Nearly half believed these tools struggled with complex tasks, underlining that the challenge now lies not in building AI, but in making it reliable in production.

This is precisely where MLOps becomes essential. MLOps (Machine Learning Operations) applies DevOps principles like CI/CD, version control, and automated testing to AI systems — making reliable deployment repeatable. In 2025, as enterprises increasingly depend on AI, MLOps is no longer optional for developers — it’s foundational.
MLOps embodies practices for the entire model lifecycle: from data preparation, model training, and validation to deployment, monitoring, and retraining. It automates labor-intensive steps, reduces deployment friction, and increases confidence in production-grade AI.
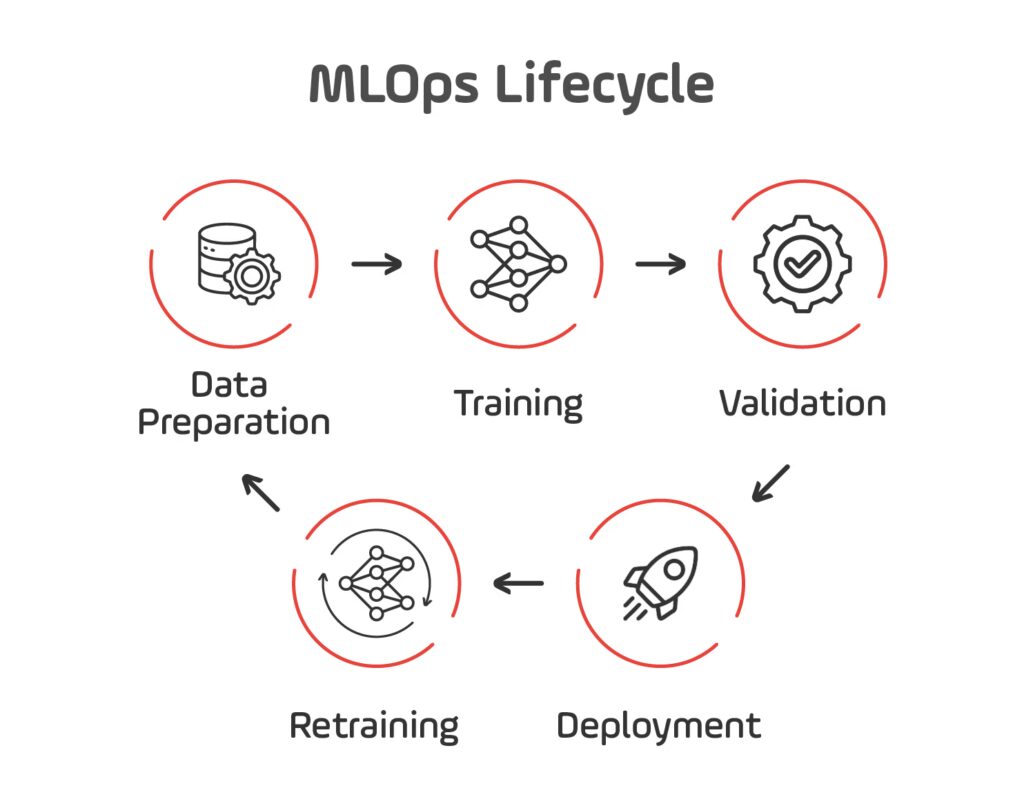
Whether you’re using MLflow, Kubeflow, or platforms like AWS SageMaker, effective MLOps helps shift AI systems from experimental to production-grade engineering — scalable, observable, and maintainable.
In this guide, you’ll first understand what MLOps truly means in 2025, then explore core MLOps tools, deployment patterns, monitoring strategies, and practical examples. If you’re a developer ready to build more reliable AI-powered applications, this is your blueprint.
Understanding MLOps in 2025
What Is MLOps?
MLOps, or Machine Learning Operations, is the engineering discipline focused on managing the entire lifecycle of ML systems. It applies DevOps practices — such as version control, automated testing, and CI/CD — to data-intensive workflows specifically for machine learning. Unlike traditional DevOps, MLOps must handle data variability, experiment tracking, model versioning, and inference monitoring.
By 2025, MLOps has become essential infrastructure. According to Gartner, 70% of enterprises will operationalize AI architectures using MLOps, with sectors like finance, healthcare, and e‑commerce adopting it to deploy AI-powered features consistently and at scale.
Why MLOps Matters Even More Now
Machine learning powers critical systems — from recommendation engines to predictive analytics. However, deploying models into production and tracking their performance over time is challenging. Teams frequently face performance degradation, inconsistent outcomes, or regulatory concerns.
MLOps addresses these challenges by introducing structure into the pipeline. It focuses on auditability, automation, and governance — helping ensure models are robust, explainable, and compliant in production settings.
Anatomy of a Production-Ready Pipeline
Here’s a typical MLOps workflow with standard tools:

- Data and Feature Versioning
Use DVC or Feast to version datasets and feature transformations for reproducibility. - Experiment Tracking
Tools like MLflow or Weights & Biases log model parameters, metrics, and outputs for systematic comparison. - Training Orchestration and Validation
Use orchestrators like Kubeflow, Airflow, or Azure ML pipelines to automate training jobs and enforce evaluation gates. - CI/CD Integration for ML
Tools such as GitHub Actions, Azure Pipelines, or Jenkins automate testing, validation, and deployment of model packages. - Model Deployment and Serving
Deploy via containerized APIs or microservices using platforms like Seldon Core, Azure ML endpoints, or SageMaker. - Monitoring and Drift Detection
Use tools like Evidently, Prometheus, or Azure ML diagnostics to track input and prediction distributions over time. - Automated Retraining Triggers
Automate retraining when drift or degradation is detected, closing the operational feedback loop.
In this architecture, each layer supports the next: versioning fosters auditability, monitoring drives retraining, and CI/CD enforces quality gates.
Real-World Example: Azure MLOps V2 Architecture
Microsoft offers a fully documented MLOps v2 architecture in Azure. It includes end-to-end CI/CD pipelines, model registry workflows, deployment automation, monitoring, and retraining triggers. This setup supports tabular, vision, and NLP workloads—creating a production-grade ML engineering pipeline. See all the details in the Azure Architecture Center here.
To implement these concepts, Microsoft provides a “How to Set Up MLOps with Azure DevOps” guide, which walks through building an end-to-end pipeline using Azure Machine Learning. Example use case: a linear regression model predicting taxi fares in New York City, with version control, training orchestration, and deployment via Azure services. Click here and view the guide.
Further, Azure’s official documentation on model management outlines how MLOps enables reproducible pipelines, model registry, metadata tracking, and deployment governance. Consult Azure’s official documentation here.
Tradeoffs and Limitations
While mature MLOps brings reliability and automation, setting it up requires significant effort. Implementing tooling, managing diverse integrations, and coordinating team responsibilities take time. There’s also a risk of overengineering if experimentation, not stability, is prioritized.
Collaboration across roles — data scientists, infra engineers, DevOps, product owners — is critical for defining acceptance criteria, drift thresholds, deployment standards, and governance workflows. For early-stage projects or exploratory data science, a lightweight versioning and deployment workflow may be more suitable initially.
Still, enterprises with mature MLOps pipelines typically see faster iteration, fewer production failures, and greater confidence in AI output — all of which scale with organizational needs.
Core Tools Powering MLOps Pipelines
Why Tool Selection Matters
Tooling is what turns MLOps from concept into production-grade practice. By 2025, the MLOps stack has matured into a modular, interoperable ecosystem. Choosing the right tools — and integrating them with your team’s workflows — is what defines your pipeline’s reliability, traceability, and scalability.
Here’s a breakdown of the five most critical categories in a modern MLOps stack, complete with working examples.
1. Experiment Tracking and Model Registry
Purpose: Record parameters, metrics, artifacts, and manage promotion of model versions.
Popular tools:
Real Example (MLflow):
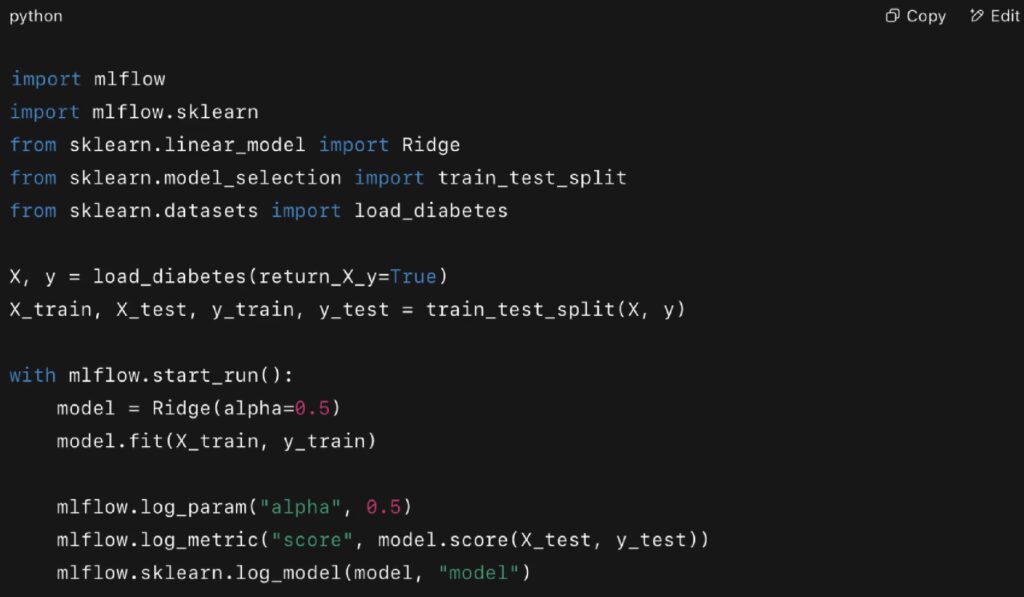
After logging, you can use the MLflow UI to register, stage, or promote models.
Tradeoff: Lightweight, easy to adopt — but needs extensions for enterprise-wide governance.
2. Pipeline Orchestration
Purpose: Define, schedule, and automate multi-step machine learning pipelines.
Popular tools:
Real Example (Kubeflow Pipelines):
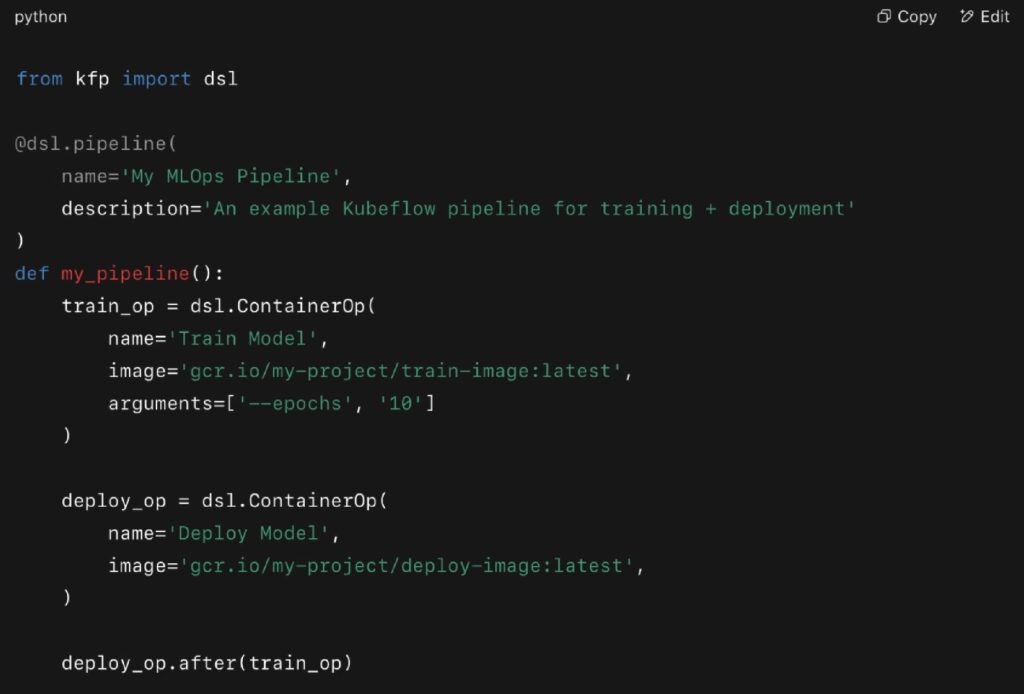
This pipeline can be versioned, scheduled, and visualized in the Kubeflow UI.
Tradeoff: Powerful but complex — requires DevOps support and Kubernetes expertise.
3. Continuous Integration / Continuous Deployment (CI/CD)
Purpose: Automate training, testing, validation, and deployment of ML models.
Popular tools:
Real Example (GitHub Actions):
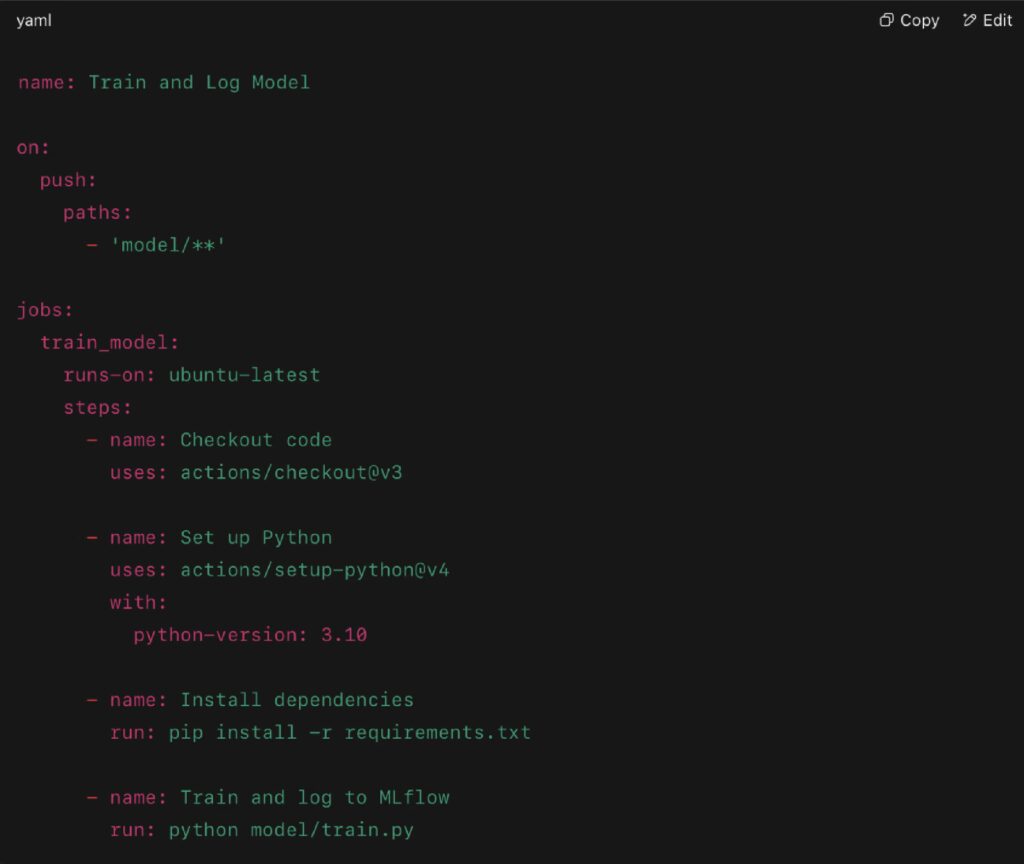
This pipeline triggers training on code changes and logs results via MLflow.
Tradeoff: General CI/CD tools require ML-specific adaptation (e.g., model versioning, artifact storage).
4. Monitoring and Drift Detection
Purpose: Observe input data, prediction accuracy, and feature drift over time.
Popular tools:
Real Example (Evidently):
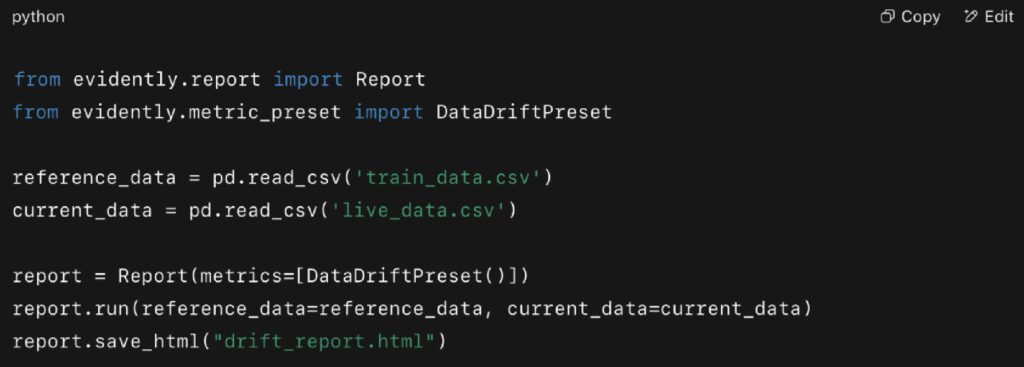
This script generates a visual drift report, tracking which features are shifting post-deployment.
Tradeoff: Some tools require labeled data; others only detect unsupervised drift, which can limit alerting accuracy.
5. Model Serving and Deployment
Purpose: Expose trained models via REST or batch endpoints, often containerized or cloud-managed.
Popular tools:
Real Example (Seldon Core):
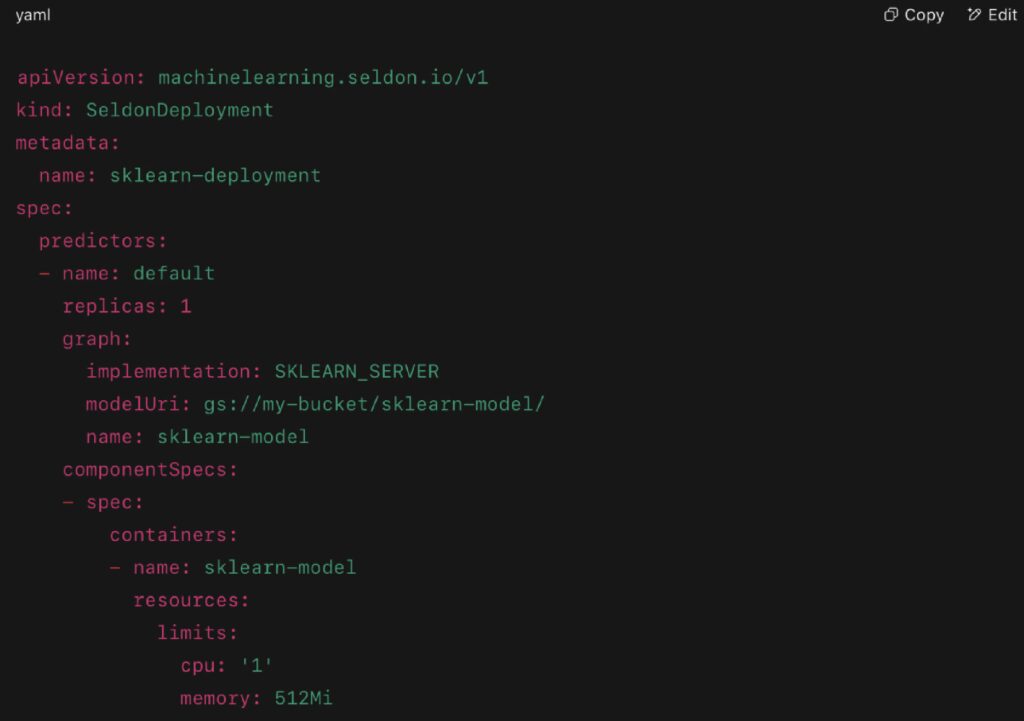
This deploys a Scikit-learn model as a live inference endpoint using Kubernetes.
Tradeoff: Kubernetes-native solutions are powerful but often overkill for smaller teams or projects.
Automating the Model Lifecycle
From Manual Scripts to Scalable AI Workflows
In early-stage ML projects, it’s common to rely on ad hoc scripts and manual steps for retraining, evaluation, and deployment. However, as data grows and models are used in production, these methods break down — leading to:
- Untracked changes and version mismatches
- Silent failures from data drift or schema changes
- Delays in reacting to model degradation
- Compliance risks (especially in finance, healthcare, and retail)
By 2025, mature teams are implementing event-driven, modular, and auditable pipelines that automate every key phase of the model lifecycle.

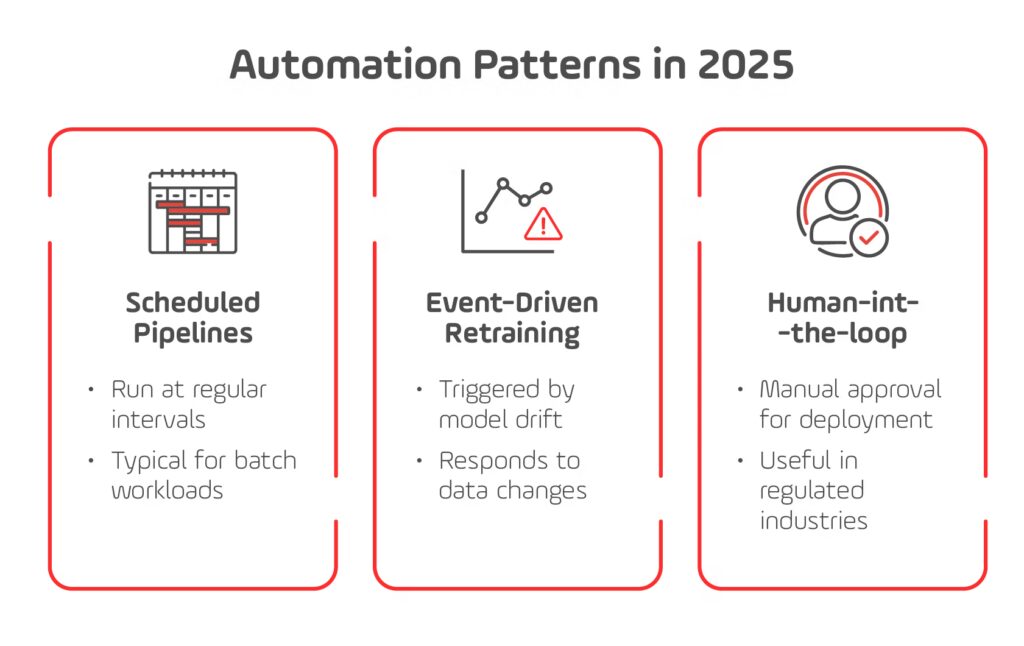
Three Automation Patterns in 2025
1. Scheduled Pipelines
Run daily or weekly to retrain or re-evaluate models using updated data. Common in marketing, finance, and batch analytics workloads.
Example:
- Airflow DAG retrains demand forecast models every Sunday night
- Evaluates MAPE/MAE using test data
- Registers and deploys only if metrics exceed last version
- All runs tracked via MLflow and stored in object storage (e.g., S3 or Azure Blob)
2. Event-Driven Retraining
Triggered by monitored events such as drift detection, schema change, data volume threshold, or manual override.
Tooling example:
- Evidently AI generates drift report
- Cloud Function or webhook triggers orchestration
- Airflow sensor or Azure Logic App triggers retraining DAG
- GitHub Actions runs model deployment
3. Human-in-the-Loop Automation
Automation handles training and monitoring, but promotion to production is manual.
Why:
Useful in regulated industries where human approval is required before deployment.
Example:
- Weekly retraining logs metrics to MLflow
- Notifies reviewer via Slack or Teams
- Reviewer approves through dashboard (e.g., Streamlit or Gradio)
- CI/CD job resumes and deploys
Real-World Architecture: Azure MLOps Lifecycle
Microsoft’s MLOps V2 blueprint illustrates how enterprises automate the lifecycle using native Azure services.
Architecture includes:
- Data versioning in Azure Data Lake
- Azure ML pipelines for training and evaluation
- Model registry with approval steps
- GitHub Actions for model promotion and deployment
- Azure Monitor to detect drift
- Azure Logic App to trigger retraining when performance thresholds are breached
Governance, Reproducibility, and Rollbacks
When automating pipelines, it’s critical to build in safety and auditability.
- Lineage tracking: MLflow, SageMaker Lineage, or Databricks ML Metadata
- Safe rollback: Use A/B testing or canary rollouts with Seldon Core, Azure ML, or KServe
- Artifact storage: Store models, logs, metrics, data versions in cloud object storage
- Immutable environments: Use Docker images or virtual environments with pinned dependencies
Best Practices
- Always validate models before promotion
- Version all components, not just code — include data and features
- Design for observability with dashboards and alerting
- Store training configurations and environment metadata
- Retrain only when meaningful metrics justify it
Common Pitfalls
- Deploying models without proper evaluation gates
- Missing or misconfigured alerts
- Overengineering early-stage workflows
- Failing to log failed runs or store partial results
- Ignoring feature versioning, causing train/serve skew
What MLOps Really Enables: Stability, Scale, and Trust
By now, it should be clear that MLOps isn’t just a trend — it’s a necessary discipline for any team deploying machine learning in production. From version control to automated retraining, MLOps enables stability, speed, and accountability across the full model lifecycle.
We explored how modern teams use tool stacks like MLflow, GitHub Actions, Airflow, and Evidently AI to manage everything from model training to real-time monitoring. We looked at how automation makes pipelines scalable, and how governance — through versioning, observability, and safe rollback — keeps systems resilient as data changes.
Perhaps most importantly, we saw that MLOps is not a one-size-fits-all solution. Whether your team is just beginning to operationalize models, or you’re looking to scale enterprise-wide AI infrastructure, adopting MLOps is a journey. The right starting point depends on where you are today.
A practical next step is to map your current ML workflow against the stages we discussed: data, training, validation, deployment, monitoring, and retraining. Identify where automation, versioning, or validation is missing — and prioritize from there.
For teams already managing production models, begin by integrating monitoring and drift detection. For teams still shipping manually, focus on adding model registry and CI/CD first.
For detailed guidance, tool recommendations, and architectural planning, check out Microsoft’s MLOps v2 reference guide, which provides a solid open foundation for implementing best practices.
And for a deeper dive into enhancing real-world model performance, explore Vercel’s Web Vitals + AI integration strategies — a practical playbook for optimizing production systems.
At Growin, we help organizations navigate this journey — designing, building, and scaling the infrastructure needed for AI systems to thrive in production. Whether you’re laying the groundwork for your first models or evolving a mature MLOps practice, our teams bring the expertise to make it happen. If you’re ready to take the next step in your MLOps journey, let’s build it together.


